

گوگل با ارائه ابزار URL Inspection Tool مدیران وبسایتها را قادر میسازد که متوجه شوند آیا ربات گوگل به صفحات سایت دسترسی دارد و میتواند آنها را بررسی کند یا خیر و … این ابزار در حقیقت یک شبیهساز است که رفتار و عملکرد ربات گوگل را در بررسی صفحات وبسایتتان برای شما شبیهسازی میکند. در این مقاله آموزشی که توسط تیم سئوی سلام وبمستر اصفهان مفصلا به توضیح ابزار Fetch as Google می پرازیم.
آشنایی با ابزار URL Inspection Tool و کاربردهای آن
کلمه Fetch در لغت به معنای “واکشی” یا “رفتن و آوردن” میباشد و Fetch as Google به این مفهوم است که شما بهصورت دستی، درخواست خواندن و بررسی صفحات دلخواهی از سایت را به ربات گوگل میدهید و ربات گوگل این عمل فراخوانی و بررسی را در همان لحظه برای صفحه موردنظر شما انجام خواهد داد.
برخی از کاربردهای ابزار Fetch as Google
به کمک ابزار Fetch as Google میتوان متوجه شد که آیا ربات گوگل به صفحات سایت دسترسی دارد و میتواند آنها را بررسی کند یا خیر؟
به کمک ابزار Fetch as Google میتوانید متوجه شوید که گوگل صفحات سایت شمارا چگونه میبیند.
ابزار Fetch as Google به شما نشان خواهد داد که گوگل چگونه اطلاعات یک صفحه را پردازش میکند و آن را برای فهرست بندی و ذخیره کردن در گوگل آماده میکند.
توسط ابزار Fetch as Google که گوگل در اختیار مدیران سایتها میگذارد، میتوانند متوجه شوند که آیا منابع موجود در یک صفحه (مانند تصاویر یا اسکریپتهای مختلف) برای دسترسی ربات گوگل مسدود شدهاند یا خیر؟
ابزار Fetch as Google مراحل بررسی و پردازشی که ربات گوگل در حالت عادی در سطح وب انجام میدهد را شبیهسازی میکند و این پروسه برای اشکالزدایی خطاهای بررسی ربات گوگل در سایت، به شما کمک خواهد کرد.
نحوه استفاده از ابزار Fetch as Google
وارد حساب کنسول جستجو خود شوید و پس از انتخاب سایت موردنظر، از منوی سمت چپ گزینه Crawl و سپس گزینه Fetch as Google را انتخاب کنید و مراحل زیر را دنبال کنید:
- در محل مشخصشده لینکی از سایت را که میخواهید ربات گوگل فراخوانی کند را وارد کنید.
بایستی لینک موردنظر را بهصورت نسبی بنویسید و نیازی به نوشتن خود دامنه اصلی نیست و درصورتیکه میخواهید عملیات فراخوانی برای صفحه اصلی سایت انجام شود کافی است که باکس متنی مربوطه را خالی بگذارید. بهعنوانمثال اگر آدرس سایت http://example.com باشد و درخواست فراخوانی و بررسی برای آدرس stores/indiana/1234.html داده شود در حقیقت لینک زیر فراخوانی و بررسی میشود:
http://example.com/stores/indiana/1234.html
برخی محدودیتهای در فراخوانی صفحات سایت توسط ابزار Fetch as Google
پروسه فراخوانی و بررسی لینکها فقط محدود به سایتی میشود که اولاً در حساب کنسول جستجو اضافه و تائید شده باشد و ثانیاً پس از ورود بهحساب کنسول جستجو از میان آدرسهای مختلف اضافهشده آن را انتخاب کرده باشید، بهعنوانمثال اگر آدرس http://example.com را انتخاب کرده باشید، لینکهای مربوط به https://example.com یا http://m.example.com را نمیتوانید توسط این بخش فراخوانی و بررسی کنید.
یکی دیگر از محدودیت های ابزار Fetch as Google این است که ابزار Fetch as Google فراخوانی اطلاعاتی چون کوکیها یا اطلاعات ذخیرهشده از صفحات لاگین و از این قبیل را برای ارسال نخواهد کرد.
این درخواست فراخوانی، لینکهای که به سایر صفحات هدایت میشوند را دنبال نخواهد کرد. درصورتیکه درخواست بررسی لینکی را دارید که آن لینک به صفحهای دیگر هدایت میشود، در ادامه در بخش “وضعیت درخواستهای ارسالشده” در قسمت Redirect توضیح دادهشده است که چطور این کار را بهصورت دستی انجام دهید.
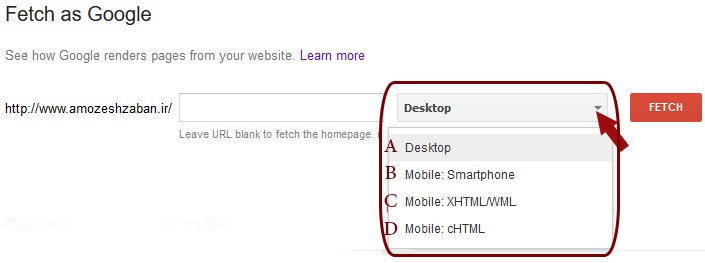
- پس از نوشتن لینک موردنظر باید یکی از انواع رباتهای گوگل که میخواهید صفحه موردنظر توسط آن برای شما فراخوانی و بررسی شود را انتخاب کنید.
با توجه به نوع صفحات و اینکه بررسی صفحه موردنظر از دید کدامیک از رباتهای گوگل برای شما اهمیت دارد، انتخابی که در این بخش انجام میشود نوع رباتی از گوگل که این عمل فراخوانی و بررسی را انجام میدهد را مشخص میکند و این انتخاب در نحوه بررسی پردازش اطلاعات آن صفحه تأثیرگذار است.
گوگل از رباتهای متنوعی استفاده میکند، این رباتها متناسب با بررسی انواع محتواها (مانند مطالب، تصاویر، فیلمها و …) و صفحات دارای انواع مختلفی هستند، همچنین از دید دستگاههای مختلفی که توسط اشخاص مورداستفاده قرار میگیرند نیز این رباتها متفاوت میباشند. ربات اصلی گوگل Googlebot نام دارد.
همانطور که در تصویر زیر ملاحظه میکنید چهار نوع ربات گوگل ارائهشده که میتوانید یکی را انتخاب کنید و صفحات موردنظر خود را از دید هر یک از این رباتهای ببینید و بررسی کنید:
Desktop
برای وبسایتها از خزنده گوگل بوت استفاده میشود.
برای اخبار از همان خزنده گوگل بوت استفاده میشود (منظور ربات گوگل نیوز نیست)
برای تصاویر از خزنده ربات گوگل برای تصاویر استفاده میشود.
برای فایلهای ویدئویی از خزنده ربات گوگل برای ویدئوها استفاده میشود.
برای صفحاتی از سایت که در آنها از کدهای سیستم تبلیغاتی گوگل استفاده شده است از خزنده ربات گوگل برای تبلیغاتی کلیکی گوگل استفاده میشود.
برای بررسی کیفیت صفحاتی از سایت که بهعنوان صفحات فرود برای تبلیغات دادهشده در گوگل
استفاده میشوند از خزنده ربات گوگل برای تبلیغات دادهشده به گوگل استفاده میشود.
Mobile: Smartphone
از خزنده مخصوص گوگل برای گوشیهای هوشمند استفاده میشود.
Mobile: XHTML/WML
از خزنده مخصوص موبایل: SAMSUNG XHTML/WML برای گوشیهای موبایل نیمههوشمند استفاده میشود. برخی موبایلهای نیمه پیشرفته که توسط Mobile: cHTML پوشش داده میشوند توسط این ربات پشتیبانی نمیشوند (با انتخاب این نوع ربات فقط میتوان صفحه موردنظر را فراخوانی کرد و قابلیت فراخوانی و پردازش صفحه پشتیبانی نمیشود.)
Mobile: cHTML
از خزنده مخصوص موبایل: DoCoMo برای زیرمجموعهای از گوشیهای موبایل نیمههوشمند ژاپنی استفاده میشود. (با انتخاب این نوع ربات فقط میتوان صفحه موردنظر را فراخوانی کرد و قابلیت فراخوانی و پردازش صفحه پشتیبانی نمیشود.)
- انتخاب یکی از دو گزینه Fetch یا Fetch and render
Fetch
توسط این گزینه در ابزار Fetch as Google صرفاً درخواست فراخوانی یک لینک از سایت توسط ربات گوگل به سرور سایت ارسال میشود و نتیجه درخواست طی جوابی از سمت سرور برای ربات گوگل ارسال میشود. این درخواست فراخوانی شامل اطلاعات و منابع اضافی داخل صفحه نمیشود. (مثلاً تصاویر یا اسکریپتهای موجود در صفحه)
عمل Fetch یک عملیات نسبتاً سریع است که میتوان از آن برای بررسی و اشکالزدایی قطعی سرور و یا مسائل امنیتی سایت استفاده کرد. با این فراخوانی میتوان متوجه شد درخواستهای که برای مشاهده صفحات سایت داده میشود خیلی سریع انجام میشود یا با مشکل برخورد میکند.
Fetch and render
با انتخاب این گزینه از ابزار Fetch as Google صفحه موردنظر توسط ربات گوگل فراخوانی (Fetch) شده، پاسخ سرور به درخواست ارسالی نمایش داده میشود (Status) و همزمان بر اساس نوع پلتفرم انتخابی (نسخه کامپیوتری یا موبایلی) صفحه موردنظر پردازش (Render) میشود. این عملیات تمامی اطلاعات و منابع موجود در صفحه مانند تصاویر و اسکریپتهای فعال در آن را هم فراخوانی، هم پردازش و اجرا میکند.
به کمک این گزینه هم میتوان متوجه شد که اشخاص دقیقاً آن صفحه را چگونه در کامپیوتر یا موبایل خود میبینند و هم اینکه گوگل چگونه آن صفحه را میبیند و آیا تفاوتی در نمایش صفحه موردنظر برای این دو (بازدیدکنندگان و ربات گوگل) وجود دارد یا خیر؟!
- پس از درخواست بررسی هر صفحهای از سایت، گزارش مربوطه در جدول پایین صفحه اضافه خواهد شد. در این جدول تاریخچه کاملی از کلیه فراخوانیهایی که برای بررسی صفحات سایت دادهشده است نمایش داده میشود.
- Path: لینک صفحهای که درخواست فراخوانی آن دادهشده است
- Google type: نوع ربات گوگل که توسط آن درخواست فراخوانی صفحه دادهشده است.
- Render requested: در نتایج این ستون مشخص میشود که صفحه موردنظر فقط فراخوانی شده یا پردازش اطلاعات صفحه نیز انجامشده است.
- Status: وضعیت درخواست و پاسخی که ربات گوگل از سرور سایت دریافت کرده است. وضعیت اولیه در حالت “pending” است و وقتی درخواست کامل اجرا شد این وضعیت تغییر خواهد کرد یا موفقیتآمیز بودن آن نمایش داده خواهد شد یا شکت خوردن عملیات درخواستی به همراه یک سری اطلاعات دیگر گزارش خواهد شد.
- Date: تاریخ ثبت درخواست.
با کلیک روی ردیف هر یک از درخواستهای ارسالشده، چنانچه آن فراخوانی موفقیتآمیز بوده باشد، اطلاعات و گزارشهای کاملی در خصوص درخواست فراخوانی آن صفحهنمایش داده میشود.
اگر صرفاً درخواست فراخوانی صفحه موردنظر را داده باشید، گزارشهای ارائهشده فقط شامل اطلاعات کلی از صفحه موردنظر است که تحت عنوان HTTP headers از سمت سرور سایت ارسال میشود و پسازآن کدهای HTML مربوط به دادههای موجود در صفحهنمایش داده میشود.
درصورتیکه درخواست فراخوانی و پردازش صفحه را داده باشید بهجز اطلاعات قبلی که در یک تب تحت عنوان “Fetching” نمایش داده میشود در تب دیگری تحت عنوان “Renering” دو پیشنمایش از پردازش صفحه موردنظر نیز ارائه میگردد، اولی پیشنمایش صفحه از دید ربات گوگل که صفحه درخواستی شمارا چگونه میبیند و یکی هم پیشنمایش صفحه از دید بازدیدکنندگان که با توجه به ابزار مورداستفاده ایشان (کامپیوتر یا موبایل) آن صفحه را چگونه خواهند دید. همچنین در پایین گزارشهای این بخش فهرستی از منابع موجود در صفحه (تصاویر، اسکریپتها و …) که دسترسی ربات گوگل برای بررسی آنها مسدود بوده است نیز نمایش داده میشود.
- درصورتیکه درخواست دادهشده با موفقیت انجام شود در جدول گزارشها گزینهای تحت عنوان “Submit to index” نمایش داده خواهد شد که میتوان توسط آن به گوگل درخواست دهید که صفحه فراخوانی شده را مجدداً بررسی (re-crawl) و فهرست بندی (re-index) کند.
این قابلیت در صورتی برای لینکی نمایش داده میشود که درخواست فراخوانی ارسالشده سه شرط زیر را داشته باشد:
نتیجه درخواست ارسالی باید یکی از سه وضعیت complete, partial یا redirected را داشته باشد. (در ادامه کلیه این وضعیتها توضیح دادهشده است)
درخواست فراخوانی لینک موردنظر بایستی توسط یکی از دو نوع ربات گوگل برای نسخههای کامپیوتری یا موبایلهای هوشمند (Desktop یا Mobile Smartphone) تنظیم شده باشد.
نتیجه و پروسه درخواست فراخوانی دادهشده، بیش از ۴ ساعت زمان نبرده باشد.
با کلیک روی گزینه “Submit to index” پنجرهای مانند تصویر نمونه باز میشود، شما میتوانید درخواست بررسی و فهرست بندی و ذخیره اطلاعات موجود در لینک درخواستی خود را به ربات گوگل بدهید:
Crawl only this URL
با انتخاب این گزینه ربات گوگل فقط همان لینک درخواستی را مجدداً بررسی خواهد کرد. حداکثر تعداد دفعاتی که میتوان از این گزینه استفاده کرد، ۵۰۰ مرتبه در ماه میباشد.
Crawl this URL and its direct links
با انتخاب این گزینه ربات گوگل نهتنها لینک درخواستی شمارا مجدد بررسی میکند بلکه کلیه صفحاتی که بهصورت مستقیم در این صفحه لینک شدهاند را نیز بررسی خواهد کرد. حداکثر تعداد دفعاتی که میتوان از این گزینه استفاده کرد، ۱۰ مرتبه در ماه میباشد.
محدودیتهای مربوط به استفاده از این دو گزینه ممکن است توسط گوگل افزایش داده شود که در همین صفحه با انتخاب هر گزینه، حداکثر مجاز و همچنین تعداد دفعاتی که در یک ماه گذشته از آن استفاده شده است نمایش داده میشود.
وضعیت درخواستهای ارسالشده توسط ابزار Fetch as Google
- Complete
نمایش این وضعیت نشان میدهد که گوگل با موفقیت با سایت ارتباط برقرار کرده و صفحه موردنظر را بهصورت کامل بررسی کرده است و همچنین برای دسترسی به منابع موجود در صفحه نیز هیچ محدودیتی نداشته است.
- Partial
Partial یکی از وضعیت درخواستهای ارسالشده توسط ابزار Fetch as Google می باشد.این وضعیت بیانگر این موضوع است که گوگل با سایت ارتباط برقرار کرده و جواب گرفته است و لینک درخواستی را نیز فراخوانی کرده است، اما نتوانسته به همه منابع موجود در آن صفحه دسترسی داشته باشد، چراکه دسترسی برخی از منابع موجود در صفحه توسط دستورات فایل robotx.txt برای ربات گوگل مسدود بوده است.
اگر درخواست شما صرفاً یک فراخوانی ساده بوده، آن را انجام دهید و درخواست پردازش صفحه مربوطه را نیز بدهید، سپس نتیجه پردازش انجامشده را ملاحظه کنید و ببینید که آیا این منابع مسدود شده منابع مهم و قابلتوجهی هستند و این عدم دسترسی گوگل به آنها باعث شده که گوگل نتواند بهصورت صحیح و کامل صفحه موردنظر را آنالیز کنند و ببینید؟
اگر چنین است باید ابتدا بررسی کنید که منابع مسدود شد تحت کنترل و مدیریت شما هستند یا خیر، اگر این منابع توسط فایل robots.txt که متعلق به خود شما است مسدود شدهاند، با ویرایش آن دسترسیهای لازم را برای ربات گوگل باز کنید و درصورتیکه منابع استفاده شده در صفحه تحت کنترل شما نمیباشند بایستی از شخصی که مدیریت آن سایت و منابع را دارد بخواهید که دسترسی خواندن این منابع را برای ربات گوگل باز کند.
پس از فراخوانی صفحه موردنظر درصورتیکه ربات گوگل نتواند به هریک از منابع موجود در صفحه دسترسی داشته باشد گزارش کاملی را در خصوص منبع مسدود شده ارائه میکند که شامل لینک منبع، نوع آن، دلیل و خطایی که باعث شده به آن منبع نتواند دسترسی داشته باشد و درجه اهمیت آن است. (برای مشاهده این اطلاعات بر روی لینک فراخوانی شده کلیک کنید در صفحه گزارشهای مربوطه در تب Rendering در پایین صفحه کلیه این گزارشها را میتوانید ملاحظه کنید)
- Redirected
Redirected یکی دیگر از وضعیت درخواستهای ارسالشده توسط ابزار Fetch as Google می باشد. این وضعیت نشان میدهد درخواست بررسی لینکی از سایت که توسط گوگل دادهشده است توسط سرور سایت به لینک و صفحهای دیگر هدایت شده است.
ابزار Fetch as Google لینکهای که بهجایی دیگر هدایت میشوند را دنبال نمیکند و درصورتیکه لینکی از سایت به لینک دیگری هدایت شود، دنبال کردن این تغییر مسیر باید بهصورت دستی و توسط خود شما انجام شود. (البته ناگفته نماند که رباتهای گوگل بهطور طبیعی وقتی در حال بررسی صفحات وب هستند کلیه ریدایرکت ها را دنبال و صفحات مربوطه را بررسی میکنند و این محدودیت فقط مربوط به درخواستهای است که توسط ابزار Fetch as Google داده میشود)
زمانی که لینکی از سایت به لینک دیگری هدایت میشود سه حالت وجود دارد:
- اگر هدایت و تغییر مسیر به لینک دیگری داخل همان سایت انجام شود، در این حالت ابزار Fetch as Google یک دکمه تحت عنوان “Follow” به شما نمایش داده خواهد شد، با کلیک بر روی آن لینک جدید در فیلد متنی جهت فراخوانی مجدد قرار میگیرید و میتوان مجدداً درخواست بررسی این لینک جدید را برای گوگل ارسال کرد.
- اگر این تغییر مسیر به سایت دیگری برود که مالک آن سایت نیز خود شما هستید (آن سایت نیز در حساب کنسول جستجو شما اضافه و تائید شده است) میتوانید روی “Follow” کلیک کنید تا لینک جدید نمایش داده شود، از لینک جدید یک کپی بگیرید، سپس به مدیریت آن سایت در حساب کنسول خود سوئیچ کنید و درخواست فراخوانی جدیدی برای این لینک در بخش Fetch as Google ثبت کنید.
- درصورتیکه هدایت به لینکی انجام میشود که متعلق به شما نیست و هیچ کنترلی بر روی آن ندارید، از ابزار Fetch as Google برای فراخوانی صفحه مربوطه نمیتوانید استفاده کنید.
ریدایرکت ها میتوانند توسط خود سرور یا توسط متا تگها و یا جاوا اسکریپتهای موجود در داخل خود صفحه موجب شوند. در جدول گزارشها بر روی لینک ریدایرکت شده کلیک کند تا جزئیات مربوط به فراخوانی انجامشده و پاسخی که توسط سرور ارسال شده است را با جزئیات بیشتر ملاحظه کنید.
 برخی از خطاهای درخواستهای ارسالشده توسط ابزار Fetch as Google
برخی از خطاهای درخواستهای ارسالشده توسط ابزار Fetch as Google
در هنگام درخواست فراخوانی یک صفحه از سایت ممکن است برخی از خطاها مانند not found یا Unreachable که مربوط به فراخوانی منابع موجود در صفحه میباشند نیز بهعنوان خطای مربوط به کل صفحه فراخوانی شده و در ستون وضعیت مربوط به لینک فراخوانی شده نمایش داده شود، لیست و توضیحات مربوط به هریک از این خطاها در ادامه توضیح دادهشده است.
- خطاهای مربوط به فراخوانی منابع موجود در صفحات سایت
درصورتیکه در جدول گزارشها، وضعیت فراخوانی انجامشده در حالت Partial باشد، بر روی ردیف مربوطه کلیک کنید تا صفحه جزئیات آن فراخوانی انجامشده بهصورت کامل نمایش داده شود. در این صفحه جدولی شامل لیست کلیه خطاهایی که اتفاق افتاده است نمایش داده میشود و معمولاً این خطاها نتیجه مسدود بودن دسترسی به برخی منابع موجود در صفحه میباشند. این خطاها شامل موارد زیر میشود:
- Not found
مفهوم این خطا این است که منبع موردنظر یافت نشده است. (کد خطای ۴۰۴ یا ۴۱۰ از سمت سرور برگشت دادهشده است) این خطا مشخص میکند که اگر توسط مرورگر خود بخواهید این صفحه را ببینید ممکن است با خطای HTTP 404 مواجه شوید.
- Not authorized
اگر ربات گوگل مجاز به دسترسی به صفحه مربوطه نباشد این خطا گزارش میشود. (بهعنوانمثال برای دسترسی به صفحه موردنظر نیاز به کلمه عبور باشد) این خطا مشخص میکند که اگر توسط مرورگر خود بخواهید این صفحه را ببینید ممکن است با خطای HTTP 403 مواجه شوید.
- DNS not found
گوگل نتوانسته منبع موردنظر فراخوانی کند چون اصلاً دامنه سایت شمارا پیدا نکرده است.
مطمئن شوید که دامنه سایت را بهصورت صحیح تایپ کردهاید.
- Blocked
فضای میزبانی وبی که منبع موردنظر بر روی آن قرار دارد، دسترسی لازم برای ربات گوگل را توسط دستورات نوشتهشده در فایل robots.txt مسدود کرده است.
منابعی که دسترسی آنها برای ربات گوگل مسدود شده است ممکن است در تجزیه، تحلیل و درک گوگل از اطلاعات آن صفحه تأثیر بگذارند و شدت اثرگذاری هریک نیز متفاوت است. همچنین مسدود بودن این منابع ممکن است در رتبهبندی آن صفحه برای جستجوهای مربوطه نیز تأثیرگذار باشد. با توجه درجه اهمیت و میزان تأثیری که هر یک از این منابع بر روی درک گوگل از صفحه مربوطه دارند، در یکی از دستهبندیهای زیر قرار میگیرند.
این میزان اهمیت در ستونی تحت عنوان “Severity” برای هر منبع مشخص و نمایش داده میشود:
- Low
منابع محدود شده با این درجه اهمیت تأثیر بسیار کمی در پردازش صفحه مربوطه دارند.
- Medium
منابع محدود شده با این درجه اهمیت در پردازش صفحه مربوطه تا حدودی تأثیرگذار میباشند.
صفحه فراخوانی شده را بررسی کنید و ببینید حذفیات یا تفاوتهای موجود بین صفحه پردازششده از دید گوگل با نمایش صفحه در حالت واقعی چقدر تفاوت دارد و این منابع مسدود شده چه میزان بر روی تجزیه تحلیل و درک گوگل از آن صفحه اثر گذاشته است
- High
منابع محدود شده با این درجه اهمیت در پردازش صفحه مربوطه تأثیر بسیار بالایی خواهند داشت و احتمالاً در نحوه بررسی و ذخیره اطلاعات صفحه مربوطه توسط گوگل نیز تأثیرگذار خواهند بود.
- (۲ تا علامت خط تیره)
خطای دادهشده مربوط به یک منبع مسدود شده نیست.
این خطای Blocked را میتوان با بروز رسانی فایل robotx.txt رفع کرد. درصورتیکه آدرس صفحه موردنظر در شاخه اصلی وبسایت قرار داشته باشد (مثلاً www.example.com و نه www.example.com/my_site) توسط ابزار robots.txt Tester که در بخش Crawl از کنسول جستجو قابلدسترس است میتوان تشخیص داد که چرا دسترسی لینک موردنظر برای گوگل بستهشده است.
- Unreachable robots.txt
زمانی این خطا نمایش داده میشود که ربات گوگل بهطورکلی نتوانسته فایل robots.txt که البته وجود دارد را بخواند و درنتیجه چون نمیداند اجازه دسترسی به کدامیک از بخشها و منابع سایت را ندارد، بررسی صفحه موردنظر کلاً رها کرده، هیچ اقدامی انجام نمیدهد و این خطا گزارش میشود.
برای رفع این خطا بایستی فایل robots.txt و دسترسی به آن را بررسی کنید.
- Unreachable
چنانچه سرور سایت در پاسخدهی به درخواست گوگل تأخیر بیش از اندازه داشته باشد این پیغام خطا توسط گوگل گزارش میشود. بایستی آنلاین بودن سرور سایت و همچنین پاسخدهی آن به درخواستهایی که سمت آن میآید بررسی شود.
- Temporarily unreachable
علت نمایش این خطا میتوانید یکی از دو مورد زیر باشد:
- زمان پاسخدهی سرور بسیار طولانی شده و درنتیجه ابزار Fetch as Google نتوانسته لینک موردنظر را فراخوانی کند.
- دستور فراخوانی توسط خود Fetch as Google کنسل شده است زیرا در همان لحظه درخواستهای متوالی و بسیار زیادی برای مشاهده لینکهای مختلفی از سایت به سرور سایت در حال ارسال بوده و برای اینکه بار اضافی بر روی سرور ایجاد نشود موقتاً درخواست فراخوانی کنسل شده است.
این عدم دسترسی موقتی فقط برای ابزار شبیهساز Fetch as Google بوده و لینک موردنظر برای خود گوگل و یا اشخاص مختلف قابلدسترس است.
- Error
یک خطای نامشخص باعث شده که گوگل نتواند درخواست فراخوانی ارسالشده را کامل کند.
اگر با این نوع خطای نامشخص برخورد کردید، لحظاتی بعد مجدداً درخواست فراخوانی خود را ارسال کنید.
