

درصورتیکه بخواهید دسترسی رباتهای موتورهای جستجو را به بخشهایی از سایت محدود کنید، میتوانید با تعریف دستورهای معینی در یک فایل به نام robots.txt این کار را انجام دهید.
رباتهای موتورهای جستجو قبل از بررسی سایت، ابتدا بررسی میکنند که فایل robots.txt در شاخه اصلی سایت موردنظر وجود دارد یا خیر
https://www.Example.com/robots.txt
درصورتیکه چنین فایلی وجود داشته باشد ابتدا دستورات آن را چک میکنند و اگر دستورات موجود در این فایل شامل محدودیتهای برای دسترسی رباتها برای مطالب، پوشهها و یا هر قسمتی از سایت باشد به آن احترام گذشته و آنها را بررسی نمیکنند.
زمانی که ربات گوگل سایت ها را بررسی می کند ممکن است در برخورد با فایل robots.txt با خطاهای مواجه شد، اول اینکه تمامی خطاهای که ربات گوگل همگام بررسی سایت ها با آن ها مواجه می شود در بخش crawl error در گوگل وبمستربخش crawl error در گوگل وبمستر به شما گزارش داده می شود و در گزارشات همین بخش نیز می توانید در قسمت Site Errors مشکلات و خطاهای اصلی سایت در ۹۰ روزه گذشته را ملاحضه کنید که قسمتی از آن مربوط به خطاهای مربوط به فایل robots.txt می باشد.
فایل Robots.txt فایلی است که در روت اصلی سایت قرار میگیرد و در آن بخشهایی از سایت که نمیخواهیم در دسترس رباتهای موتورهای جستجو قرار بگیرند، تعریف و مشخص میشوند.
فایل Robots.txt توسط یک سری استانداردها و دستورات خاص بهصورت ساده و کوتاه نوشته میشود که میتواند نحوه دسترسی انواع رباتهای موتورهای جستجو را به بخشهای مختلف وبسایت مشخص کند.
فایل Robots.txt برای مدیریت دسترسی به چه نوع فایلهایی کاربرد دارد؟
مطالب و محتواهای سایت
زمانی که رباتهای موتورهای جستجو سایتی را بررسی کنند، ترافیکی را بر روی سرور آن سایت خواهند داشت، توسط فایل robots.txt میتوان ترافیک ایجادشده برای بررسی کلیه فایلهای غیر تصویری (صفحات وب) را کنترل کرد تا سرور سایت بیش از اندازه مشغول نشود و یا رباتهای جستجوگر وقت و انرژی خود را بر روی بررسی مطالبی نگذارند که اهمیت زیادی نداشته و یا تکراری هستند.
دقت کنید استفاده از robotx.txt بدین معنا نیست که صفحات سایت مخفی باشند و یا در نتایج جستجو نمایش داده نشوند. ممکن است لینک صفحاتی که دسترسی بررسی آنها توسط robots.txt برای ربات گوگل مسدود شده باشد در سایر صفحات یا سایتهای دیگر قرار داشته باشد و زمانی که آن صفحات توسط ربات گوگل بررسی میشوند، خود آن لینک نیز مشاهده و در فهرست بندیهای گوگل ذخیره و حتی در نتایج جستجو نیز نمایش داده شود، بدون اینکه هیچ ارتباطی به فایل robots.txt داشته باشد.
اگر میخواهید صفحهای کلاً در نتایج جستجو نیاید باید از روشهای دیگری مانند پسورد گذاری برای آن صفحه یا استفاده از برچسب noindex برای آن صفحه استفاده کنید.
فایلهای تصویری
توسط robots.txt میتوان جلوی نمایش تصاویر سایت را در نتایج موتورهای جستجو گرفت. (البته این نیز نمیتواند باعث شود که سایر سایتها و یا اشخاص نتوانند به آن تصاویر لینک دهند)
منابع موجود در صفحات
توسط robots.txt میتوان دسترسی به تصاویر غیرضروری، اسکریپتها یا فایلهای css و … را که در صفحات سایت استفاده میشوند را نیز مسدود کرد.
البته دسترسی به این منابع را در صورتی مسدود کنید که بر روی نحوه بارگذاری و نمایش این صفحات تأثیری نداشته باشند. چنانچه نبود این منابع بر روی درک ربات گوگل از صفحات تأثیر بگذارد و اجازه ندهد گوگل تجزیهوتحلیل مناسبی از صفحات مربوطه داشته باشد پیشنهاد میشود دسترسی به این منابع را مسدود نکنید.
محدودیتهای استفاده از فایل robots.txt
قبل از اینکه اقدام به ساخت و استفاده از فایل robots.txt برای سایت خود کنید، بهتر است با محدودیتها و همچنین ریسک مسدود کردن دسترسی لینکها با این روش آشنا شوید. گاهی اوقات چنانچه میخواهید لینکهایی از سایتتان در سطح وب قابل پیدا شدن نباشند و رباتهای موتورهای جستجو نیز نتوانند آنها را بررسی و در فهرستهای خود ذخیره کنند بهتر است یک سری مکانیسمهای دیگر را مورداستفاده قرار دهید.
txtصرفاً یک راهنما برای رباتهای موتورهای جستجو میباشد
دستورالعملهای موجود در فایل robots.txt نمیتوانند اجباری بر رفتار و عملکرد رباتها داشته باشند. این دستورالعملها بهنوعی یک سری راهنما برای رباتهای موتورهای جستجو میباشند که مشخص میکنند چه بخشهایی از سایت نباید بررسی شوند. درحالیکه ربات گوگل و سایر رباتهای قانونمند در وب به دستورالعملهای موجود در فایلهای robots.txt احترام میگذارند برخی رباتهای دیگر هستند که اصلاً به این قوانین پایبند نبوده و طبق دستورالعملهای موجود در robots.txt عمل نمیکنند، بنابراین اگر اطلاعاتی در سایت خود دارید که میخواهید کاملاً دور از دسترس رباتهای موتورهای جستجو باشند بهتر است از سایر روشهای امنتر جهت مسدودسازی دسترسی استفاده کنید، بهعنوانمثال تعریف کلمه عبور بر روی فایلها و یا لینکهای موردنظر.
تفسیرهای مختلف رباتها از دستورات فایل txt
اگرچه کلیه رباتهای قانونمند در سطح وب به دستورات موجود در فایل robots.txt پایبند هستند اما ممکن است تفسیرهای متفاوتی از دستورات موجود داشته باشند. همچنین شما باید دستورات و نحو مناسب برای هر رباتی را نیز بدانید چراکه برخی از رباتها ممکن است دستوراتی را بهصورت کامل درک نکنند و حتی دستورالعملهای مختص به خود را داشته باشند.
دستورات txt نمیتوانند مانع لینک دهی سایر سایتها به سایت شما شوند
با وجود اینکه گوگل صفحات و محتواهایی که توسط robotx.txt دسترسی به آنها مسدود شده است را نه بررسی میکند و نه فهرست بندی، اما ممکن است لینک یکی از همین فایلها و یا صفحاتی که اجازه دسترسی به آنها مسدود شده است را درجایی دیگر از وب (سایر صفحات یا سایتهای دیگر) پیدا کند و با توجه به متن لینک شده یا عنوان کمکی مربوطه، آن لینک و توضیحات وابسته را فهرست بندی و ذخیره کند و حتی در نتایج جستجو نیز نمایش دهد.
نحوه ساخت فایل txt
برای اینکه بتوانید یک فایل robots.txt برای سایت خود بسازید باید به شاخه اصلی سایت در سرور مربوطه دسترسی داشته باشید. اگر به سرور یا شاخه اصلی سایت در فضای میزبانی وب خود دسترسی ندارید باید به شخص یا شرکتی که سرور سایت را از ایشان تهیه کردهاید درخواست دهید تا دسترسیهای لازم را به شما بدهند.
چنانچه نمیتوانید به شاخه اصلی سایت در سرور مربوطه دسترسی داشته باشید باید از سایر روشهای جایگزین مانند تعریف کلمه عبور روی فایل موردنظر و یا بهکارگیری برچسبهای مربوطه در کدهای html صفحات موردنیاز استفاده کنید.
توسط ابزار robots.txt Tester موجود در کنسول جستجو گوگل هم میتوان فایل robots.txt را ایجاد و یا در صورت وجود آن را ویرایش کرد. همچنین توسط این ابزار میتوان کلیه تغییراتی که بر روی فایل robots.txt میخواهید انجام دهید را تست و بررسی کنید.
تست و ذخیره کردن فایل robots.txt
برای ایجاد و ذخیره کردن فایل robots.txt باید قوانین زیر را رعایت کنید تا ربات گوگل و هم سایر رباتها بتوانند آن را بهخوبی شناسایی و پیدا کنند و هم بتوانند دستورات آن را بخوانند. با سلام وبمستر همراه باشید تا شما را با نحوه ذخیره کردن فایل robots.txt آشنا کنیم.
- فایل robotx.txt باید بهصورت یک فایل متنی با پسوند txt ذخیره شود.
- این فایل باید در بالاترین شاخه سایت قرار بگیرد. (روت اصلی سایت)
- اسم فایل دقیقاً باید robots.txt باشد.
ذخیره کردن فایل robots.txt
مثال: اگر آدرس سایت example.com باشد فایل robots.txt باید در شاخه اصلی سایت ذخیره شود تا رباتها بتوانند آن را شناسایی و بررسی کنند، یعنی در آدرس زیر:
http://www.example.com/robots.txt
اما اگر فایل robots.txt در آدرس نمونه زیر قرار بگیرد هیچیک از رباتها نمیتوانند آن را شناسایی کنند:
http://www.example.com/not_root/robots.txt
ابزار تست فایل robots.txt به شما نشان خواهد داد که آیا فایل robots.txt دسترسی رباتهای گوگل به برخی لینکهای سایت را مسدود کرده است یا خیر! بهعنوانمثال اگر میخواهید دسترسی به لینک تصویری را مسدود کنید تا در نتایج جستجو گوگل نمایش داده نشود، میتوانید از این ابزار استفاده کنید و تست کنید که آیا ربات جستجو تصاویر گوگل (Googlebot-Image) به لینک آن تصویر دسترسی دارد یا خیر!
میتوان لینکی از سایت را در ابزار robots.txt tester وارد کرد تا این ابزار دقیقاً مانند ربات گوگل عمل کرده و فایل robots.txt سایت را بررسی کند و تائیدیه مسدود بودن یا نبودن لینک موردنظر برای دسترسی رباتهای گوگل را مشخص کند.
تست فایل robots.txt
وارد حساب کنسول جستجو خود شوید و از بخش Crawl گزینه robots.txt tester را انتخاب کنید. چنانچه سایت شما فایل robots.txt را داشته باشد در ویرایشگر وسط صفحه میتوانید کدهای مربوط به این فایل را که گوگل از آن استخراج کرده است را ملاحظه کنید، بخشهای مختلف موجود در ابزار robots.txt tester در تصویر نمونه صفحه بعد شمارهگذاری شدهاند که در ادامه به توضیح هر یک خواهیم پرداخت: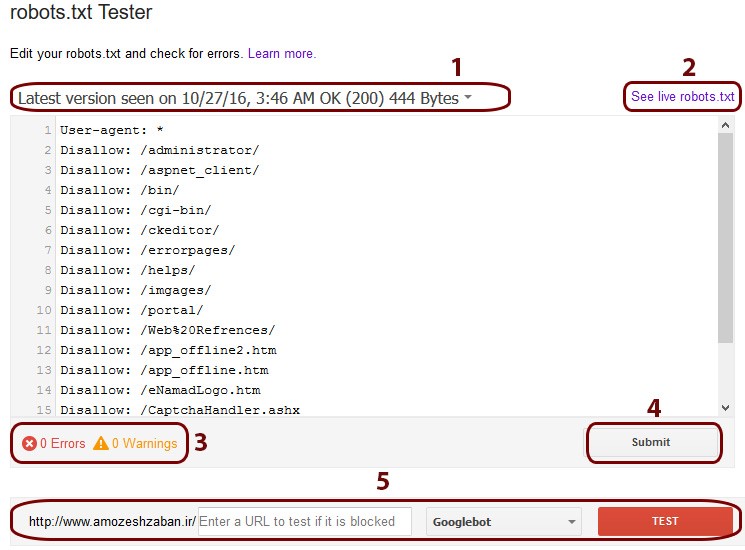
- گزارشی از آخرین تاریخ و زمانی که ربات گوگل فایل txt سایت را بررسی کرده است.
- توسط این گزینه شما میتوانید درخواست فراخوانی مستقیم و لحظهای کدها و دستورات موجود در فایل txt سایت خود را به گوگل بدهید.
- تعداد خطاها و هشدارهای مربوط به فایل txt سایت
- ارسال درخواست بررسی سریع فایل جدید txt به گوگل (قابلاستفاده برای زمانی که تغییراتی در فایل robots.txt میدهید)
- ابزار تست فایل txt سایت را میتوانید ملاحظه کنید.
برای بررسی و تست عملکرد فایل robots.txt میتوان طبق روال زیر عمل کرد:

- در فیلد متنی که در پایین صفحه گزارشهای این بخش قرار دارد لینکی از سایت خود را کپی کنید.
- توسط لیست کشویی نوع ربات گوگل که میخواهید شبیهسازی تست بر اساس آن ربات انجام شود را انتخاب کنید.
- روی دکمه test کلیک کنید تا تست لینک درخواستی انجام شود. پس از ارسال درخواست تست یکی از دو حالت زیر نمایش داده خواهد شد:
- ALLOWED
نمایش این وضعیت بدین معناست که ربات گوگل اجازه دسترسی و خواندن لینک درجشده را دارد.
- BLOCKED
نمایش این وضعیت بدین معناست که دسترسی ربات گوگل به لینک درجشده مسدود است و اجازه دسترسی و خواندن آن را ندارد و در ویرایشگر میان صفحه، خط مربوط به دستوری که باعث مسدود شدن این دسترسی شده است را مشخص میکند.
میتوان توسط ویرایشگر ارائهشده در همین صفحه کدهای دستوری مربوط به فایل robots.txt را ویرایش کرده و مجدد تستهای موردنیاز را انجام داد.
آشنایی با دستورات robots.txt
سادهترین فایل robots.txt را میتوان به کمک دستورات robots.txt زیر ایجاد کرد:
User-agent
نام رباتها موتورهای جستجو یا نرمافزارهای خزنده موجود در سطح وب میباشد.
لیست کامل رباتهای موجود در سطح وب را میتوانید از لینک زیر مشاهده کنید:
http://www.robotstxt.org/db.html
Disallow
دستوری که مشخص میکند رباتها به چه لینک یا بخشی از سایت نباید دسترسی داشته باشند.
البته یک دستور دیگر به نام Allow نیز در فایل robots.txt استفاده میشود و آنهم زمانی است که میخواهیم لینکی از سایت توسط رباتها بررسی شود اما آن لینک در داخل لینک والد دیگری قرار دارد که دسترسی به لینک والد برای رباتها مسدود شده است.
گوگل رباتهای متعددی دارد، بهعنوانمثال Googlebot که برای جستجو صفحات وب استفاده میشود یا Googlebot-image که برای جستجو تصاویر توسط گوگل مورداستفاده قرار میگیرد. معمولاً بیشتر رباتهای گوگل از قوانینی که برای ربات اصلی گوگل یعنی Googlebot وضع میشود پیروی میکنند؛ اما بااینحال میتوان بدون در نظر گرفتن این موضوع، قوانینی را مختص هریک از انواع رباتهای گوگل در فایل robots.txt نوشت.
نحوه بهکارگیری و نوشتن این دستورات robots.txt:
User-agent: [نام رباطی که میخواهیم دستورات نوشتهشده را رعایت کند]
Disallow: [لینکی که میخواهیم دسترسی ربات (ها) موردنظر به آن مسدود شود]
Allow: [لینکی که میخواهیم توسط ربات موردنظر بررسی شود اما در یک شاخه والد مسدود شده قرار دارد]
User-agent: * [استفاده از کاراکتر * جهت مخاطب قرار دادن همه رباتهای موجود سطح وب میباشد]
در پیادهسازی و ساخت فایل robots.txt میتوان ورودیهای متعددی را داشت، میتوان چندین دستور Disallow را برای چندین User-agent مختلف بهکارگیری کرد و … بهطورکلی با روشهای متعددی میتوان قوانین موردنظر خود را برای دسترسی یا عدم دسترسی رباتهای موتورهای جستجو برای بخشهای دلخواه سایت نوشت.
دستورات robots.txt قابلاستفاده برای مسدود کردن دسترسیها
| درخواستهای مسدودسازی | نمونه کد و دستورات robots.txt |
| مسدود کردن دسترسی کل سایت با کاراکتر اسلش (/) | Disallow: / |
| مسدود کردن دسترسی به کل محتویات یک پوشه یا یک شاخه از سایت با ذکر نام پوشه بین دو کاراکتر اسلش | Disallow: /sample-directory/ |
| مسدود کردن دسترسی به یک صفحه مشخص با ذکر لینک صفحه موردنظر بعد از کاراکتر اسلش | Disallow: /private_file.html |
| مسدود کردن دسترسی به یک تصویر خاص برای ربات مخصوص تصاویر گوگل |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
| مسدود کردن دسترسی به کل تصاویر سایت برای ربات مخصوص تصاویر گوگل |
User-agent: Googlebot-Image Disallow: / |
| مسدود کردن دسترسی ربات گوگل به نوع خاصی از فایلها بهعنوانمثال فایلهایی با پسوند.gif |
User-agent: Googlebot Disallow: /*.gif$ |
| اگر در صفحات سایت تبلیغات گوگل (AdSense) داشته باشیم و بخواهیم دسترسی رباتها را مسدود کنیم اما به ربات Mediapartners-Google اجازه دسترسی بدهیم تا بتواند صفحات را بررسی کند و بتواند تصمیم بگیرد که چه تبلیغاتی را برای بازدیدکنندگان سایت نمایش دهد. |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
توجه: دستورات مورداستفاده در robots.txt به حروف کوچک و بزرگ حساس میباشند.
بهعنوانمثال:
دستور Disallow: /file.asp دسترسی به صفحه http://www.example.com/file.asp را مسدود میکند اما اجازه دسترسی به صفحه http://www.example.com/File.asp همچنان وجود دارد. همچنین ربات گوگل از فاصلههای اضافی و دستورات ناشناخته و غیراستاندارد استفاده شده در robots.txt چشمپوشی میکند.
پس از ایجاد فایل robots.txt برای یک وبسایت، رباتهای موتورهای جستجو طبق آن عمل کرده و بخشهایی که اجازه دسترسی ندارند را بررسی نخواهند کرد؛ اما تا قبل از ایجاد و اضافه کردن این فایل ممکن است تمامی فایلها و صفحاتی که دسترسی آنها الآن مسدود شده است توسط موتورهای جستجو بررسی و فهرست بندی شده باشند. باید صبور باشید تا با مرور زمان لیست آنها از گوگل خارج شود.
 برخی الگوهای دستوری برای ساده کردن دستورات robots.txt
برخی الگوهای دستوری برای ساده کردن دستورات robots.txt
| الگوهای دستوری | نمونه کد و دستورات robots.txt |
| مسدود کردن فایلهایی که رشتهای از حروف مشابه در اسم خود دارند با استفاده از کاراکتر ستاره (*) در قسمتی از نام که مشابه و تکراری است.
بهعنوانمثال مسدود کردن تمام زیرشاخههای سایت که با کلمه “private” شروع میشوند: |
User-agent: Googlebot Disallow: /private*/ |
| مسدود کردن دسترسی لینکهایی که در آنها کاراکتر علامت سؤال (؟) وجود دارد.
بهعنوانمثال نمونه کد روبرو دسترسی ربات گوگل به لینکهای که بعد از دامنه سایت یک رشته دلخواه، سپس کاراکتر علامت سؤال و مجدد هر رشتهای دیگری بعد از آن آمده باشد را مسدود میشود. |
User-agent: Googlebot Disallow: /*? |
| مسدود کردن دسترسی به لینکهایی که به یک فرمت خاص ختم میشوند با استفاده از کاراکتر دلار ($)
بهعنوانمثال نمونه کد روبرو دسترسی به لینکهای از سایت که به.xls ختم میشوند را مسدود میکند. |
User-agent: Googlebot Disallow: /*.xls$
|
| مسدود کردن دسترسی برای الگوهایی که هم شامل دستور Allow هستند و هم Disallow
بهعنوانمثال در نمونه کد روبرو کاراکتر؟ مشخصکننده یک session ID است، معمولاً لینکهایی که شامل این آیدیها میشوند باید برای رباتها مسدود شوند تا مشکل بررسی صفحات تکراری پیش نیاید. بااینحال ممکن است لینک برخی از صفحات (که میخواهیم توسط رباتها بررسی شوند) به کاراکتر؟ ختم شوند که بایستی از ترکیب دو دستور Allow و Disallow استفاده کنیم. |
User-agent: * Allow: /*?$ Disallow: /*? توضیح: دستور Allow: /*?$ اجازه بررسی لینکهایی را میدهد که به کاراکتر؟ ختم میشوند و دستور Disallow: / *? اجازه بررسی تمامی لینکهایی که شامل کاراکتر؟ میشوند را مسدود میکند. |
برای ایجاد و ذخیره کردن فایل robots.txt باید قوانین زیر را رعایت کنید تا ربات گوگل و هم سایر رباتها بتوانند آن را بهخوبی شناسایی و پیدا کنند و هم بتوانند دستورات آن را بخوانند. با سلام وبمستر همراه باشید تا شما را با نحوه ذخیره کردن فایل robots.txt آشنا کنیم.
- فایل robotx.txt باید بهصورت یک فایل متنی با پسوند txt ذخیره شود.
- این فایل باید در بالاترین شاخه سایت قرار بگیرد. (روت اصلی سایت)
- اسم فایل دقیقاً باید robots.txt باشد.
<![endif]–>
ذخیره کردن فایل robots.txt
مثال: اگر آدرس سایت example.com باشد فایل robots.txt باید در شاخه اصلی سایت ذخیره شود تا رباتها بتوانند آن را شناسایی و بررسی کنند، یعنی در آدرس زیر:
http://www.example.com/robots.txt
اما اگر فایل robots.txt در آدرس نمونه زیر قرار بگیرد هیچیک از رباتها نمیتوانند آن را شناسایی کنند:
http://www.example.com/not_root/robots.txt
میتوان لینکی از سایت را در ابزار robots.txt tester وارد کرد تا این ابزار دقیقاً مانند ربات گوگل عمل کرده و فایل robots.txt سایت را بررسی کند و تائیدیه مسدود بودن یا نبودن لینک موردنظر برای دسترسی رباتهای گوگل را مشخص کند.
دقت کنید استفاده از robotx.txt بدین معنا نیست که صفحات سایت مخفی باشند و یا در نتایج جستجو نمایش داده نشوند. ممکن است لینک صفحاتی که دسترسی بررسی آنها توسط robots.txt برای ربات گوگل مسدود شده باشد در سایر صفحات یا سایتهای دیگر قرار داشته باشد و زمانی که آن صفحات توسط ربات گوگل بررسی میشوند، خود آن لینک نیز مشاهده و در فهرست بندیهای گوگل ذخیره و حتی در نتایج جستجو نیز نمایش داده شود، بدون اینکه هیچ ارتباطی به فایل robots.txt داشته باشد.
نحوه ارسال و اطلاعرسانی فایل بهروز شده robots.txt برای گوگل
در صفحه مربوط به ابزار Tester robotx.txt در کنار ویرایشگر موجود در این بخش گزینهای تحت عنوان Submit وجود دارد که توسط آن میتوان بهسادگی ارسال و اطلاعرسانی فایل بهروز شده robots.txt برای گوگل را بدهید. با کلیک بر روی این گزینه یک پنجره جدید باز خواهد شد که حاوی دستورالعملهای مربوطه است:
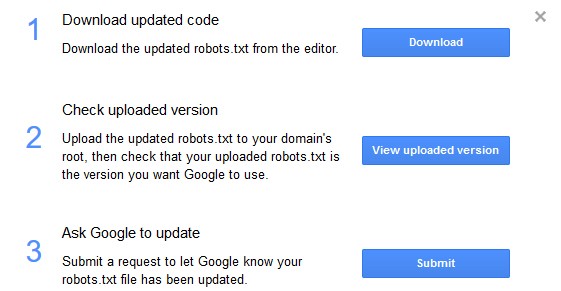
در پنجره بازشده برای ارسال و اطلاعرسانی فایل بهروز شده robots.txt برای گوگل مراحل زیر را انجام دهید:
- توسط گزینه “Download” فایل ویرایش شده txt را دانلود کنید.
- فایل txt دانلود شده را در ریشه و شاخه اصلی سایت خود با همین نام و با همین فرمت متنی بارگذاری کنید. (لینک دسترسی به این فایل دقیقاً باید مانند: www.Example.com/robots.txt باشد)
اگر دسترسی به هاست و شاخه اصلی مربوط به دامنه سایت خود ندارید و نمیتوانید فایل robots.txt را در شاخه اصلی سایت بارگذاری کنید بایستی با مدیر سرور و فضای میزبانی سایت خود تماس بگیرید تا این تغییرات را برای شما انجام دهد.
مثلاً اگر آدرس صفحه اصلی سایت شما subdomain.example.com/site/example/ باشد بهاحتمال زیاد نمیتوان فایل robots.txt را در آدرس subdomain.example.com/robots.txt بروز رسانی کنید مگر اینکه مالک و مدیر example.com/ تغییرات لازم را انجام دهد.
- پس از بروز رسانی و آپلود فایل جدید txt روی گزینه “view uploaded version” کلیک کنید تا بتوانید فایل robots.txt موجود بر روی سرور سایت را بهصورت زنده ببینید و مطمئن شوید که این فایل همان فایل جدیدی است که میخواهید گوگل آن را بررسی کند.
- در آخر با کلیک روی گزینه “submit” میتوانید درخواست بررسی مجدد فایل txt را برای گوگل ارسال کنید و به گوگل اعلام کنید که تغییرات موردنظر روی فایل robots.txt انجامشده است.
- جهت یک تست نهایی و برای اینکه مطمئن شوید فایل جدید txt با موفقیت توسط گوگل بررسیشده است. مجدد صفحه مربوط به ابزار robots.txt tester را در مرورگر خود باز کنید و دستورات tobots.txt را در ویرایشگر این بخش چک کنید. همچنین بعد از باز کردن مجدد این صفحه در بالای صفحه یک برچسب زمانی نمایش داده میشود که با کلیک روی آن میتوانید تاریخ آخرین باری که گوگل فایل robots.txt سایت را بررسی کرده است را ملاحظه کنید.
در ارسال و اطلاعرسانی فایل بهروز شده robots.txt برای گوگل دقت کنید که دسترسی بخشها یا منابعی از سایت که گوگل برای بررسی بهینه سایت به آنها نیاز دارد را مسدود نسازید و این را به خاطر داشته باشید که هیچ الزامی به داشتن فایل robots.txt برای سایت وجود ندارد. رباتهای جستجو وقتی به سایتی میرسند برای اینکه بدانند اجازه دسترسی و بررسی چه بخشها یا فایلهایی از سایت را ندارند، ابتدا بررسی میکنند که آن سایت فایل robotx.txt در شاخه اصلی خود دارد یا نه. چنانچه سایتی اصلاً این فایل را نداشته باشد، رباتها همچنان طبق روال عادی و روند کاری خود کلیه بخشها و محتویات سایت را بررسی و فهرست بندی خواهند کرد.
